Software
conoce como
software[1] al equipamiento lógico o soporte lógico de un
sistema informático; comprende el conjunto de los componentes
lógicos necesarios que hacen posible la realización de tareas específicas, en contraposición a los componentes físicos, que son llamados
hardware.
Los componentes lógicos incluyen, entre muchos otros, las
aplicaciones informáticas; tales como el
procesador de texto, que permite al usuario realizar todas las tareas concernientes a la edición de textos; el
software de sistema, tal como el
sistema operativo, que, básicamente, permite al resto de los programas funcionar adecuadamente, facilitando también la interacción entre los componentes físicos y el resto de las aplicaciones, y proporcionando una
interfaz con el usuario.
Etimología
Software (pronunciación
AFI:
[soft'ɣware]) es una palabra proveniente del
inglés (literalmente: partes blandas o suaves), que en español no posee una traducción adecuada al contexto, por lo cual se la utiliza asiduamente sin traducir y así fue admitida por la
Real Academia Española (RAE).
[2] Aunque no es estrictamente lo mismo, suele sustituirse por expresiones tales como
programas (informáticos) o
aplicaciones (informáticas).
[3]
Software es lo que se denomina
producto en
Ingeniería de Software.
[4]
Definición de software
Existen varias definiciones similares aceptadas para software, pero probablemente la más formal sea la siguiente:
Es el conjunto de los programas de cómputo, procedimientos, reglas, documentación y datos asociados que forman parte de las operaciones de un sistema de computación.
Extraído del estándar 729 del
IEEE[5]Considerando esta definición, el concepto de software va más allá de los programas de computación en sus distintos estados:
código fuente,
binario o
ejecutable; también su documentación, los datos a procesar e incluso la información de usuario forman parte del software: es decir,
abarca todo lo intangible, todo lo «no físico» relacionado.
El término «software» fue usado por primera vez en este sentido por
John W. Tukey en
1957. En la ingeniería de software y las
ciencias de la computación, el software es toda la
información procesada por los
sistemas informáticos: programas y
datos.
El concepto de leer diferentes secuencias de instrucciones (
programa) desde la
memoria de un dispositivo para controlar los cálculos fue introducido por
Charles Babbage como parte de su
máquina diferencial.
La teoría que forma la base de la mayor parte del software moderno fue propuesta por
Alan Turing en su ensayo de 1936, «Los números computables», con una aplicación al problema de decisión.
Clasificación del software
Si bien esta distinción es, en cierto modo, arbitraria, y a veces confusa, a los fines prácticos se puede clasificar al software en tres grandes tipos:
- Software de sistema: Su objetivo es desvincular adecuadamente al usuario y al programador de los detalles del sistema informático en particular que se use, aislándolo especialmente del procesamiento referido a las características internas de: memoria, discos, puertos y dispositivos de comunicaciones, impresoras, pantallas, teclados, etc. El software de sistema le procura al usuario y programador adecuadas interfaces de alto nivel, herramientas y utilidades de apoyo que permiten su mantenimiento. Incluye entre otros:
- Software de programación: Es el conjunto de herramientas que permiten al programador desarrollar programas informáticos, usando diferentes alternativas y lenguajes de programación, de una manera práctica. Incluye entre otros:
- Software de aplicación: Es aquel que permite a los usuarios llevar a cabo una o varias tareas específicas, en cualquier campo de actividad susceptible de ser automatizado o asistido, con especial énfasis en los negocios. Incluye entre otros:
Proceso de creación del software
Se define como Proceso al conjunto ordenado de pasos a seguir para llegar a la solución de un problema u obtención de un producto, en este caso particular, para lograr la obtención de un producto software que resuelva un problema.
El proceso de creación de software puede llegar a ser muy complejo, dependiendo de su porte, características y criticidad del mismo. Por ejemplo la creación de un sistema operativo es una tarea que requiere proyecto, gestión, numerosos recursos y todo un equipo disciplinado de trabajo. En el otro extremo, si se trata de un sencillo programa (por ejemplo, la resolución de una ecuación de segundo orden), éste puede ser realizado por un solo programador (incluso aficionado) fácilmente. Es así que normalmente se dividen en tres categorías según su tamaño (
líneas de código) o costo: de Pequeño, Mediano y Gran porte. Existen varias metodologías para
estimarlo, una de las más populares es el sistema
COCOMO que provee métodos y un software (programa) que calcula y provee una estimación de todos los costos de producción en un «proyecto software» (relación horas/hombre, costo monetario, cantidad de líneas fuente de acuerdo a lenguaje usado, etc.).
Considerando los de gran porte, es necesario realizar complejas tareas, tanto técnicas como de gerencia, una fuerte gestión y análisis diversos (entre otras cosas), por lo cual se ha desarrollado una ingeniería para su estudio y realización: es conocida como
Ingeniería de Software.
En tanto que en los de mediano porte, pequeños equipos de trabajo (incluso un avezado
analista-programador solitario) pueden realizar la tarea. Aunque, siempre en casos de mediano y gran porte (y a veces también en algunos de pequeño porte, según su complejidad), se deben seguir ciertas etapas que son necesarias para la construcción del software. Tales etapas, si bien deben existir, son flexibles en su forma de aplicación, de acuerdo a la metodología o
Proceso de Desarrollo escogido y utilizado por el equipo de desarrollo o por el analista-programador solitario (si fuere el caso).
Los «
procesos de desarrollo de software» poseen reglas preestablecidas, y deben ser aplicados en la creación del software de mediano y gran porte, ya que en caso contrario lo más seguro es que el proyecto o no logre concluir o termine sin cumplir los objetivos previstos, y con variedad de fallos inaceptables (fracasan, en pocas palabras). Entre tales «procesos» los hay ágiles o livianos (ejemplo
XP), pesados y lentos (ejemplo
RUP) y variantes intermedias; y normalmente se aplican de acuerdo al tipo y porte del software a desarrollar, a criterio del líder (si lo hay) del equipo de desarrollo. Algunos de esos procesos son
Programación Extrema (en inglés
eXtreme Programming o XP),
Proceso Unificado de Rational (en inglés Rational Unified Process o RUP), Feature Driven Development (
FDD), etc.
Cualquiera sea el «proceso» utilizado y aplicado al desarrollo del software (RUP, FDD, etc), y casi independientemente de él, siempre se debe aplicar un «modelo de ciclo de vida».
[6]
Se estima que, del total de proyectos software grandes emprendidos, un 28% fracasan, un 46% caen en severas modificaciones que lo retrasan y un 26% son totalmente exitosos.
[7]
Cuando un proyecto fracasa, rara vez es debido a fallas técnicas, la principal causa de fallos y fracasos es la falta de aplicación de una buena metodología o proceso de desarrollo. Entre otras, una fuerte tendencia, desde hace pocas décadas, es mejorar las metodologías o procesos de desarrollo, o crear nuevas y concientizar a los profesionales en su utilización adecuada. Normalmente los especialistas en el estudio y desarrollo de estas áreas (metodologías) y afines (tales como modelos y hasta la gestión misma de los proyectos) son los Ingenieros en Software, es su orientación. Los especialistas en cualquier otra área de desarrollo informático (analista, programador, Lic. en Informática, Ingeniero en Informática, Ingeniero de Sistemas, etc.) normalmente aplican sus conocimientos especializados pero utilizando modelos, paradigmas y procesos ya elaborados.
Es común para el desarrollo de software de mediano porte que los equipos humanos involucrados apliquen sus propias metodologías, normalmente un híbrido de los procesos anteriores y a veces con criterios propios.
El proceso de desarrollo puede involucrar numerosas y variadas tareas
[6] , desde lo administrativo, pasando por lo técnico y hasta la gestión y el gerenciamiento. Pero casi rigurosamente siempre se cumplen ciertas
etapas mínimas; las que se pueden resumir como sigue:
- Captura, Elicitación[8] , Especificación y Análisis de requisitos (ERS)
- Diseño
- Codificación
- Pruebas (unitarias y de integración)
- Instalación y paso a Producción
- Mantenimiento
En las anteriores etapas pueden variar ligeramente sus nombres, o ser más globales, o contrariamente, ser más refinadas; por ejemplo indicar como una única fase (a los fines documentales e interpretativos) de «análisis y diseño»; o indicar como «implementación» lo que está dicho como «codificación»; pero en rigor, todas existen e incluyen, básicamente, las mismas tareas específicas.
En el apartado 4 del presente artículo se brindan mayores detalles de cada una de las listadas etapas.
Modelos de proceso o ciclo de vida
Para cada una de las fases o etapas listadas en el ítem anterior, existen sub-etapas (o tareas). El
modelo de proceso o
modelo de ciclo de vida utilizado para el desarrollo define el orden para las tareas o actividades involucradas
[6] también definen la coordinación entre ellas, enlace y realimentación entre las mencionadas etapas. Entre los más conocidos se puede mencionar:
modelo en cascada o secuencial,
modelo espiral,
modelo iterativo incremental. De los antedichos hay a su vez algunas variantes o alternativas, más o menos atractivas según sea la aplicación requerida y sus requisitos.
[7]
Modelo cascada
Este, aunque es más comúnmente conocido como
modelo en cascada es también llamado «modelo clásico», «modelo tradicional» o «modelo lineal secuencial».
El modelo en cascada puro
difícilmente se utiliza tal cual, pues esto implicaría un previo y absoluto conocimiento de los requisitos, la no volatilidad de los mismos (o rigidez) y etapas subsiguientes libres de errores; ello sólo podría ser aplicable a escasos y pequeños desarrollos de sistemas. En estas circunstancias, el paso de una etapa a otra de las mencionadas sería sin retorno, por ejemplo pasar del Diseño a la Codificación implicaría un diseño exacto y sin errores ni probable modificación o evolución: «codifique lo diseñado que no habrán en absoluto variantes ni errores». Esto es utópico; ya que intrínsecamente el software es de carácter evolutivo, cambiante y difícilmente libre de errores, tanto durante su desarrollo como durante su vida operativa.
[6]

Fig. 2 - Modelo cascada puro o secuencial para el ciclo de vida del software.
Algún cambio durante la ejecución de una cualquiera de las etapas en este modelo secuencial implicaría reiniciar desde el principio todo el ciclo completo, lo cual redundaría en altos costos de tiempo y desarrollo. La figura 2 muestra un posible esquema de el modelo en cuestión.
[6]
Sin embargo, el modelo cascada en algunas de sus variantes es uno de los actualmente más utilizados
[9] , por su eficacia y simplicidad, más que nada en software de pequeño y algunos de mediano porte; pero nunca (o muy rara vez) se lo usa en su forma pura, como se dijo anteriormente. En lugar de ello, siempre se produce alguna
realimentación entre etapas, que no es completamente predecible ni rígida; esto da oportunidad al desarrollo de productos software en los cuales hay ciertas incertezas, cambios o evoluciones durante el ciclo de vida. Así por ejemplo, una vez capturados (elicitados) y especificados los requisitos (primera etapa) se puede pasar al diseño del sistema, pero durante esta última fase lo más probable es que se deban realizar ajustes en los requisitos (aunque sean mínimos), ya sea por fallas detectadas, ambigüedades o bien por que los propios requisitos han cambiado o evolucionado; con lo cual se debe retornar a la primera o previa etapa, hacer los pertinentes reajustes y luego continuar nuevamente con el diseño; esto último se conoce como realimentación. Lo normal en el modelo cascada será entonces la aplicación del mismo con sus etapas realimentadas de alguna forma, permitiendo retroceder de una a la anterior (e incluso poder saltar a varias anteriores) si es requerido.
De esta manera se obtiene un «modelo cascada realimentado», que puede ser esquematizado como lo ilustra la figura 3.

Fig. 3 - Modelo cascada realimentado para el ciclo de vida.
Lo dicho es, a grandes rasgos, la forma y utilización de este modelo, uno de los más usados y populares.
[6] El modelo Cascada Realimentado resulta muy atractivo, hasta ideal, si el proyecto presenta alta rigidez (pocos o ningún cambio, no evolutivo), los requisitos son muy claros y están correctamente especificados.
[9]
Hay más variantes similares al modelo: refino de etapas (más etapas, menores y más específicas) o incluso mostrar menos etapas de las indicadas, aunque en tal caso la faltante estará dentro de alguna otra. El orden de esas fases indicadas en el ítem previo es el lógico y adecuado, pero adviértase, como se dijo, que normalmente habrá realimentación hacia atrás.
El modelo lineal o en cascada es el paradigma más antiguo y extensamente utilizado, sin embargo las críticas a él (ver desventajas) han puesto en duda su eficacia. Pese a todo, tiene un lugar muy importante en la
Ingeniería de software y continúa siendo el más utilizado; y siempre es mejor que un enfoque al azar.
[9]
Desventajas del modelo cascada:
[6]
- Los cambios introducidos durante el desarrollo pueden confundir al equipo profesional en las etapas tempranas del proyecto. Si los cambios se producen en etapa madura (codificación o prueba) pueden ser catastróficos para un proyecto grande.
- No es frecuente que el cliente o usuario final explicite clara y completamente los requisitos (etapa de inicio); y el modelo lineal lo requiere. La incertidumbre natural en los comienzos es luego difícil de acomodar.[9]
- El cliente debe tener paciencia ya que el software no estará disponible hasta muy avanzado el proyecto. Un error detectado por el cliente (en fase de operación) puede ser desastroso, implicando reinicio del proyecto, con altos costos.
Modelos evolutivos
El software evoluciona con el tiempo. Los requisitos del usuario y del producto suelen cambiar conforme se desarrolla el mismo. Las fechas de mercado y la competencia hacen que no sea posible esperar a poner en el mercado un producto absolutamente completo, por lo que se debe introducir una versión funcional limitada de alguna forma para aliviar las presiones competitivas.
En esas u otras situaciones similares los desarrolladores necesitan modelos de progreso que estén diseñados para acomodarse a una evolución temporal o progresiva, donde los requisitos centrales son conocidos de antemano, aunque no estén bien definidos a nivel detalle.
En el modelo Cascada y Cascada Realimentado no se tiene en cuenta la naturaleza evolutiva del software, se plantea como estático con requisitos bien conocidos y definidos desde el inicio.
[6]
Los evolutivos son modelos iterativos, permiten desarrollar versiones cada vez más completas y complejas, hasta llegar al objetivo final deseado; incluso evolucionar más allá, durante la fase de operación.
Los modelos «iterativo incremental» y «espiral» (entre otros) son dos de los más conocidos y utilizados del tipo evolutivo.
[9]
Modelo iterativo incremental
En términos generales, podemos distinguir, en la figura 4, los pasos generales que sigue el proceso de desarrollo de un producto software. En el modelo de ciclo de vida seleccionado, se identifican claramente dichos pasos. La Descripción del Sistema es esencial para especificar y confeccionar los distintos incrementos hasta llegar al Producto global y final. Las actividades concurrentes (Especificación, Desarrollo y Validación) sintetizan el desarrollo pormenorizado de los incrementos, que se hará posteriormente.

Fig. 4 - Diagrama genérico del desarrollo evolutivo incremental.
El diagrama 4 nos muestra en forma muy esquemática, el funcionamiento de un ciclo iterativo incremental, el cual permite la entrega de versiones parciales a medida que se va construyendo el producto final.
[6] Es decir, a medida que cada incremento definido llega a su etapa de operación y mantenimiento. Cada versión emitida incorpora a los anteriores incrementos las funcionalidades y requisitos que fueron analizados como necesarios.
El incremental es un modelo de tipo evolutivo que está basado en varios ciclos Cascada realimentados aplicados repetidamente, con una filosofía iterativa.[9] En la figura 5 se muestra un refino del diagrama previo, bajo un esquema temporal, para obtener finalmente el esquema del Modelo de ciclo de vida Iterativo Incremental, con sus actividades genéricas asociadas. Aquí se observa claramente cada ciclo cascada que es aplicado para la obtención de un incremento; estos últimos se van integrando para obtener el producto final completo. Cada incremento es un ciclo Cascada Realimentado, aunque, por simplicidad, en la figura 5 se muestra como secuencial puro.
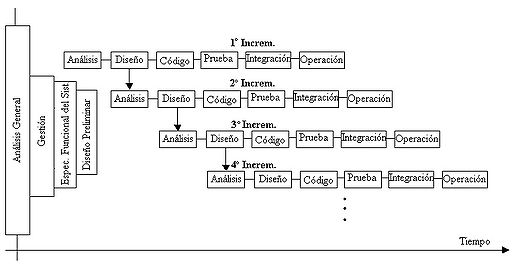
Fig. 5 - Modelo iterativo incremental para el ciclo de vida del software,.
Se observa que existen actividades de desarrollo (para cada incremento) que son realizadas en paralelo o concurrentemente, así por ejemplo, en la figura, mientras se realiza el diseño detalle del primer incremento ya se está realizando en análisis del segundo. La figura 5 es sólo esquemática, un incremento no necesariamente se iniciará durante la fase de diseño del anterior, puede ser posterior (incluso antes), en cualquier tiempo de la etapa previa. Cada incremento concluye con la actividad de «operación y mantenimiento» (indicada «Operación» en la figura), que es donde se produce la entrega del producto parcial al cliente. El momento de inicio de cada incremento es dependiente de varios factores: tipo de sistema; independencia o dependencia entre incrementos (dos de ellos totalmente independientes pueden ser fácilmente iniciados al mismo tiempo si se dispone de personal suficiente); capacidad y cantidad de profesionales involucrados en el desarrollo; etc.
Bajo este modelo se entrega software «por partes funcionales más pequeñas», pero reutilizables, llamadas incrementos. En general cada incremento se construye sobre aquel que ya fue entregado.
[6]
Como se muestra en la figura 5, se aplican secuencias Cascada en forma escalonada, mientras progresa el tiempo calendario. Cada secuencia lineal o Cascada produce un incremento y a menudo el primer incremento es un sistema básico, con muchas funciones suplementarias (conocidas o no) sin entregar.
El cliente utiliza inicialmente ese sistema básico intertanto, el resultado de su uso y evaluación puede aportar al plan para el desarrollo del/los siguientes incrementos (o versiones). Además también aportan a ese plan otros factores, como lo es la priorización (mayor o menor urgencia en la necesidad de cada incremento) y la dependencia entre incrementos (o independencia).
Luego de cada integración se entrega un producto con mayor funcionalidad que el previo. El proceso se repite hasta alcanzar el software final completo.
Siendo iterativo,
con el modelo incremental se entrega un producto parcial pero completamente operacional en cada incremento, y no una parte que sea usada para reajustar los requerimientos (como si ocurre en el
modelo de construcción de prototipos).
[9]
El enfoque incremental resulta muy útil con baja dotación de personal para el desarrollo; también si no hay disponible fecha límite del proyecto por lo que se entregan versiones incompletas pero que proporcionan al usuario funcionalidad básica (y cada vez mayor). También es un modelo útil a los fines de evaluación.
Nota: Puede ser considerado y útil, en cualquier momento o incremento incorporar temporalmente el paradigma
MCP como complemento, teniendo así una mixtura de modelos que mejoran el esquema y desarrollo general.
Ejemplo:
- Un procesador de texto que sea desarrollado bajo el paradigma Incremental podría aportar, en principio, funciones básicas de edición de archivos y producción de documentos (algo como un editor simple). En un segundo incremento se le podría agregar edición más sofisticada, y de generación y mezcla de documentos. En un tercer incremento podría considerarse el agregado de funciones de corrección ortográfica, esquemas de paginado y plantillas; en un cuarto capacidades de dibujo propias y ecuaciones matemáticas. Así sucesivamente hasta llegar al procesador final requerido. Así, el producto va creciendo, acercándose a su meta final, pero desde la entrega del primer incremento ya es útil y funcional para el cliente, el cual observa una respuesta rápida en cuanto a entrega temprana; sin notar que la fecha límite del proyecto puede no estar acotada ni tan definida, lo que da margen de operación y alivia presiones al equipo de desarrollo.
Como se dijo, el Iterativo Incremental es un modelo del tipo evolutivo, es decir donde se permiten y esperan probables cambios en los requisitos en tiempo de desarrollo; se admite cierto margen para que el software pueda evolucionar. Aplicable cuando los requisitos son medianamente bien conocidos pero no son completamente estáticos y definidos, cuestión esa que si es indispensable para poder utilizar un modelo Cascada.
El modelo es aconsejable para el desarrollo de software en el cual se observe, en su etapa inicial de análisis, que posee áreas bastante bien definidas a cubrir, con suficiente independencia como para ser desarrolladas en etapas sucesivas. Tales áreas a cubrir suelen tener distintos grados de apremio por lo cual las mismas se deben priorizar en un análisis previo, es decir, definir cual será la primera, la segunda, y así sucesivamente; esto se conoce como «definición de los incrementos» con base en priorización. Pueden no existir prioridades funcionales por parte del cliente, pero el desarrollador debe fijarlas de todos modos y con algún criterio, ya que basándose en ellas se desarrollarán y entregarán los distintos incrementos.
El hecho de que existan incrementos funcionales del software lleva inmediatamente a pensar en un esquema de desarrollo
modular, por tanto este modelo facilita tal paradigma de diseño.
En resumen, un modelo incremental lleva a pensar en un desarrollo modular, con entregas parciales del producto software denominados «incrementos» del sistema, que son escogidos según prioridades predefinidas de algún modo. El modelo permite una implementación con refinamientos sucesivos (ampliación o mejora). Con cada incremento se agrega nueva funcionalidad o se cubren nuevos requisitos o bien se mejora la versión previamente implementada del producto software.
Este modelo brinda cierta flexibilidad para que durante el desarrollo se incluyan cambios en los requisitos por parte del usuario, un cambio de requisitos propuesto y aprobado puede analizarse e implementarse como un nuevo incremento o, eventualmente, podrá constituir una mejora/adecuación de uno ya planeado. Aunque si se produce un cambio de requisitos por parte del cliente que afecte incrementos previos ya terminados (detección/incorporación tardía)
se debe evaluar la factibilidad y realizar un acuerdo con el cliente, ya que puede impactar fuertemente en los costos.
La selección de este modelo permite realizar
entregas funcionales tempranas al cliente (lo cual es beneficioso tanto para él como para el grupo de desarrollo). Se priorizan las entregas de aquellos módulos o incrementos en que surja la necesidad operativa de hacerlo, por ejemplo para cargas previas de información, indispensable para los incrementos siguientes.
[9]
El modelo iterativo incremental no obliga a especificar con precisión y detalle absolutamente todo lo que el sistema debe hacer, (y cómo), antes de ser construido (como el caso del cascada, con requisitos congelados). Sólo se hace en el incremento en desarrollo. Esto torna más manejable el proceso y reduce el impacto en los costos. Esto es así, porque en caso de alterar o rehacer los requisitos, solo afecta una parte del sistema. Aunque, lógicamente, esta situación se agrava si se presenta en estado avanzado, es decir en los últimos incrementos.
En definitiva, el modelo facilita la incorporación de nuevos requisitos durante el desarrollo.
Con un paradigma incremental se reduce el tiempo de desarrollo inicial, ya que se implementa funcionalidad parcial. También provee un impacto ventajoso frente al cliente, que es la entrega temprana de partes operativas del software.
El modelo proporciona todas las ventajas del modelo en cascada realimentado, reduciendo sus desventajas sólo al ámbito de cada incremento.
El modelo incremental no es recomendable para casos de sistemas de
tiempo real, de alto nivel de seguridad, de
procesamiento distribuido, o de alto índice de riesgos.
Hardware
Hardware (pronunciación
AFI:
/ˈhɑːdˌwɛə/ ó
/ˈhɑɹdˌwɛɚ/) corresponde a todas las partes tangibles de un
sistema informático: sus componentes eléctricos, electrónicos, electromecánicos y mecánicos;
[1] sus cables, gabinetes o cajas,
periféricos de todo tipo y cualquier otro elemento físico involucrado; contrariamente, el soporte lógico es intangible y es llamado
software. El término es propio del
idioma inglés (literalmente traducido:
partes duras), su traducción al español no tiene un significado acorde, por tal motivo se la ha adoptado tal cual es y suena; la
Real Academia Española lo define como «Conjunto de los componentes que integran la parte material de una computadora».
[2] El término, aunque es lo más común, no solamente se aplica a una computadora tal como se la conoce, ya que, por ejemplo, un
robot, un
teléfono móvil, una
cámara fotográfica o un
reproductor multimedia también poseen
hardware (y
software), por lo que es más correcto el uso de
sistema informático.
[3] [4]
El término
hardware tampoco correspondería a un sinónimo exacto de
«componentes informáticos», ya que esta última definición se suele limitar exclusivamente a las piezas y elementos internos, independientemente de los periféricos.
La historia del
hardware del computador se puede clasificar en cuatro generaciones, cada una caracterizada por un cambio
tecnológico de importancia. Este
hardware se puede clasificar en:
básico, el estrictamente necesario para el funcionamiento normal del equipo; y
complementario, el que realiza funciones específicas.
Un sistema informático se compone de una
unidad central de procesamiento (CPU), encargada de procesar los datos, uno o varios
periféricos de entrada, los que permiten el ingreso de la información y uno o varios periféricos de salida, los que posibilitan dar salida (normalmente en forma visual o
auditiva) a los
datos procesados.













